Docker 실습 쿠팡 크롤링
간식 정리해서 이름 , 수량 개수 , 금액 등을 excel로 정리해서 올려야 함.
매월 1번씩 하는데 한번 만들어놓고 랜덤으로 과자 조건 줘서 시킬 수 있게 자동화 해보자.
url뒤에 /robots.txt를 붙이면 해당 웹사이트의 "robots.txt" 파일 요청
크롤링하도록 허용하거나 차단하고 있는지를 확인 가능

## Google
User-agent: Googlebot
Allow: /vp/products/
Allow: /np/categories/
Allow: /np/search?q=*
Disallow: /vm/direct-orders/
Disallow: /vm/cart/
Disallow: /gppu-choice-widget?itemId=*
Disallow: /vendor-items/
Disallow: /other-seller-jsonUser-agent : Googlebot 구글 봇에 대해 규칙이 적용되어 있음 (*이면 모든 봇에 대해 규칙 적용)
Allow : 경로에 있는 페이지 크롤링해도 좋다.
Disallow : 경로에 있는 페이지는 크롤링 하지 말아달라.
내가 볼 곳은 상품페이지 인데 Allow로 되어있는것을 확인할 수 있음

내 user-agent 확인 방법
개발자 도구를 열고 navigator.userAgent 입력한다.

1. Selenium 설치
pip install seleniumpip : 파이썬 패키지 설치하고 관리할 수 있는 관리 도구
자동화 테스트 셀레니움 설치
2. chromedriver_autoinstaller 설치
pip install chromedriver-autoinstallerChromeDriver의 버전을 자동으로 맞추어주는 라이브러리.
셀레니움을 Chrome에서 자동화할 때, ChromeDriver의 버전은 Chrome버전과 일치해야되므로 버전 호환성 문제를 해결해줌.
$ pip show chromedriver-autoinstaller
Name: chromedriver-autoinstaller
Version: 0.6.4
Summary: Automatically install chromedriver that supports the currently installed version of chrome.
Home-page: https://github.com/yeongbin-jo/python-chromedriver-autoinstaller
Author: Yeongbin Jo
Author-email: iam.yeongbin.jo@gmail.com
License: MIT
Location: C:\Users\user\AppData\Local\Programs\Python\Python312\Lib\site-packages
Requires: packaging
Required-by:제대로 설치 됐는지 확인하려면 show 명령어 통해 확인
3. 파이썬 코드 작성
import time
import random
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
import chromedriver_autoinstaller시간,랜덤값 그리고 셀레니움 필요 설정 import
- webdriver : 웹 브라우저 제어 객체 (필수)
- By : 요소 찾을 때 (ID, CLASS_NAME , CSS_SELECTOR) javascript로 생각하면 documents.getElementsById 같은 느낌
- Keys : 키보드 입력 모방할 수 있는 기능 제공
처음실행될 때 호환성 문제를 해결하기 위해서 ChromeDriver를 자동으로 설치 해야함.
chromedriver_autoinstaller.install()
나는 Docker에서 사용할것이므로 GUI가 필요없다. 그러므로 옵션 추가해줘서 백그라운드에서 작업하게 해줘야함.
options.add_argument("headless")
options.add_argument("no-sandbox")
options.add_argument("disable-dev-shm-usage")headless 옵션 : GUI를 렌더링하지 않기 때문에 CPU 메모리 절약(속도 빠름).
no-sandbox 옵션 : 샌드박스 모드를 비활성화(도커에서 샌드박스 제대로 동작하지 않을 수 있어 비활성화 시킨다.
샌드박스 : 애플리케이션 안전하게 실행하기 위해 격리된 환경
disable-dev-shm-usage 옵션 : /dev/shm가 공유메모리인데 비활성화 시킴 파일 시스템을 통해 데이터를 저장하도록 하는 것
이제 옵션 설정다되었으면 해당 인스턴스를 생성하여 제어한다.
driver = webdriver.Chrome(options=options)
그리고 아까 import했던 selenium의 by문법을 이용하여 쿠팡의 input 박스를 찾음

searchBox = driver.find_element(By.Name, "q")
searchBox.send_keys("과자")
searchBox.send_keys(Keys.RETURN)RETURN은 ENTER를 의미함 몇가지 더 있는데
Keys.TAB - 탭 키
Keys.BACKSPACE - 백스페이스 키
Keys.DELETE - 삭제 키
Keys.HOME - 홈 키
Keys.END - 엔드 키
Keys.PAGE_DOWN - 페이지 다운 키
Keys.PAGE_UP - 페이지 업 키
Keys.ARROW_UP - 위쪽 화살표 키
Keys.ARROW_DOWN - 아래쪽 화살표 키
등등이 있음.
검색 후 페이지 로드되는 것 기다려야함
time.sleep(2)
내가 원하는 가격 설정 후 while문을 이용해서 채워질때까지 반복문을 실행



data-is-rocket 값이 true이면 로켓배송 아니면 일반배송임

해당 div에 있는 name 값과 price-value가 필요하니 변수 선언해서 가져온다
price는 누적해서 내가 설정한 값을 넘기면 안되므로 int형으로 바뀐 후 누적해서 더해준다.
#랜덤으로 로켓배송 상품 선택
item = random.choice(rocket_items)
try:
#상품 이름 금액 추출
item_name = item.find_element(By.CSS_SELECTOR, "div.name").text
item_price_txt = item.find_element(By.CSS_SELCTOR, "strong.price-value").text
#int로 변환
item_price = int(item_price_txt.replace(",", ""))
# total_price 넘으면 안됨
if now_price + item_price <= total_price:
product_list.append({"name" : item_name , "price" : item_price})
now_price += item_price
items_cnt += 1
except Exception as e:
print("예외가 발생하였습니다." , e)
2개를 찾았으면 끝나고 다음 페이지에서 또 2개를 채워줘야함 , 클릭한 뒤 랜더링 되는 시간 2초 빼준다.
try:
next_button = driver.find_element(By.CSS_SELECTOR, "a.btn-next")
next_button.click()
time.sleep(2) # 랜더링 대기
except Exception as e:
print("예외가 발생하였습니다." , e)
엑셀로 만들어서 쓰기 위해 Pandas 라이브러리 추가해준다.
pandas가 할 수 있는 일
1. 엑셀 파일 읽고 쓰는 작업
2. CSV 파일을 읽고 쓰는 작업
3. 데이터 정렬 , 그룹화 , 필터링 등등
4. 수치형 데이터 분석과 같은 다양한 데이터로 반환
pip install pandas판다스깔고 임포트 시킨 후 사용
df = pd.DataFrame(product_list) # product_list를 DataFrame으로 변환
df.to_excel("product_list.xlsx", index=False) # 엑셀 파일로 저장
도커 파이썬 슬림이용
슬림 버전은 불필요한 툴과 패키지 최소화하여 이미지 크기 줄였음
FROM python:3.10.15-slimRUN apt-get update && apt-get install -y \
curl \
unzip \
chromium-driver \
&& rm -rf /var/lib/apt/lists/*필요한 소프트웨어 패키지를 설치
apt-get update는 패키지 목록 최신으로
apt-get install -y는 필요한 패키지를 설치. -y는 모든 응답에 "y"로 대답하여 넘어가는 것
curl : 웹에서 파일 다운로드 또는 API 호출을 통해 데이터를 받아오거나 전송할 때 주로 사용
WORKDIR 작업디렉토리 생성
COPY로 먼저 txt 복사 이후 내용 설치 (캐시 비우기 옵션 추가 이미지 가볍게 하기 위해)
컨테이너 안에서 실행시켜야되므로 COPY해서 py실행
WORKDIR /app
# requirements.txt 복사 및 라이브러리 설치
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
# 크롤러 스크립트 복사
COPY crawlling.py .
# 환경 변수 설정
ENV CHROME_BIN=/usr/bin/chromium
ENV CHROMEDRIVER_PATH=/usr/bin/chromedriver
# 크롤러 실행
CMD ["python", "crawler.py"]
빌드하고 실행하는데 에러뜬다.

확인해보니 크롤러 실행하는 파일 이름 달랐음

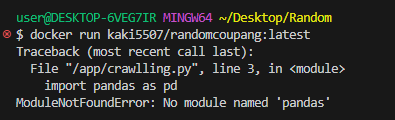
확인해보니 requirements.txt에 필요한 파이썬 패키지를 넣지 않았음
하지만 실행해도 아무일 일어나지 않음
도커 컨테이너에서 생성한 파일은 컨테이너 파일 시스템에 저장! 컨테이너가 종료되면 파일또한 역시 삭제 됨. 그래서 삭제 전에
호스트 시스템에서 확인하고 싶다면 실행된 상태에서 파일을 복사해야함.
docker cp <컨테이너_ID>:/app/파일명 /호스트/경로/C:\Users\user호스트 경로는 바탕화면에 할거면 이런식으로 자기 컴퓨터에 맞게 cp라는 명령어로 copy복사한다는 것
또는 호스트의 디렉토리와 공유하는 방법이 있음

접근이 거부되었다고 나옴

내부코드에서 driver = webdriver.WebDriver 문법 맞지 않다고 나옴 수정 필요

페이지로드가 되기전에 p를 불러서 그런지 계속해서 오류가 난다
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC추가하여 페이지 랜더링 시간 기다려보도록 함.

그래도 찾지 못했음 input 태그를 찾는데 오래걸리는걸까?
searchBox = WebDriverWait(driver, 100000000000).until(
EC.presence_of_element_located((By.CSS_SELECTOR, "input[name='q']"))
)input 태그의 name "q"를 찾으라고 하니 바로 찾고 다른 라인으로 넘어갔다.
pandas
selenium
chromedriver-autoinstaller
openpyxlopenpyx1도 엑셀이용하려면 라이브러리 필요하므로 추가해준다.
차단당해서 안되는건지 input태그를 잘잡지 못함
# 랜덤 User-Agent 리스트
user_agents = [
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:89.0) Gecko/20100101 Firefox/89.0",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/15.0 Safari/605.1.15",
"Mozilla/5.0 (Linux; Android 10; SM-G950F) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.77 Mobile Safari/537.36",
"Mozilla/5.0 (iPhone; CPU iPhone OS 14_0 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/14.0 Mobile/15E148 Safari/604.1",
# 추가 User-Agent를 여기에 추가할 수 있습니다.
]
# 랜덤으로 User-Agent 선택
random_user_agent = random.choice(user_agents)
options.add_argument(f"user-agent={random_user_agent}")셀레니움 옵션에 추가해주고 다시 빌드한 후 실행해봄.
일단 잘 돌아가는 것을 볼 수 있는데 예외가 계속해서 발생했음

user-agent가 또 막혔는지 잘 못찾고 코드 수정을 더 해줌
from fake_useragent import UserAgentfake_useragent로 더 많은 user-agent 생성했음
스크롤을 못해서 데이터를 못가져오는건가 싶어서 sleep()도 충분히 넣어줌
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);") # 페이지 끝까지 스크롤스크롤 하는 명령어 까지
print("1 : " + driver.page_source) # 현재 DOM 페이지 표시왜 못찾는지 보기위해서 현재 찾은 dom을 전부 분석해봄

쿠팡으로간다음 검색창에 "과자"를 입력해야되는데 입력창을 못잡는 것 같음 headless 모드여서 그런진 모르겠는데
그래서 과자를 입력 한뒤 작업부터 하니깐 불러와지긴하는데 name값이랑 value값을 잡지 못함
#driver.get("https://www.coupang.com/") #랜더링이 전체가 되지않고 카테고리까지 돼서 수정
driver.get("https://www.coupang.com/np/search?component=&q=%EA%B3%BC%EC%9E%90&channel=user")
로그 분석을 다시해야함
페이지의 html이 많은 관계로 로그볼 수 있는 줄 수를 늘린다.
docker logs --tail 1000 < 컨테이너 아이디 >
full 로그 분석 결과 분석 너무 많음 태그가
docker logs e2c7604b6d95 | grep "price-value"docker id를 가지고 특정 키워드 분석 가능
너무 실행이 안돼서 이것저것 수정 많이해보고 로그 다 찍어보았다.
1. 랜더링 대기 시간 랜덤
ime.sleep(random.uniform(3, 7)) # 랜더링 대기2. 랜덤으로 상품 선택 시 태그 값 상세하게
price_wraps = WebDriverWait(driver, 20).until(
EC.presence_of_all_elements_located((By.CSS_SELECTOR, '#productList .search-product'))
)3. 선택된 요소 리스트에서 제거
price_wraps.remove(price_wrap) # 선택된 요소를 리스트에서 제거
여기서도 예외는 발생하지만 페이지가 넘어가면서 채우긴 하는데 시간이 오래걸림
예외발생하면서 채우는데 일단 결과값까지 떨어지는지 확인하고 예외 수정
200000원 전까지 계속해서 도는거여서 로직 변경이 필요
# total_price를 넘지 않도록 체크
if now_price + item_price <= total_price:
product_list.append({"name": item_name, "price": item_price})
now_price += item_price
items_cnt += 1이 부분의 if문이 필요가 없다 안그러면 딱 맞지 않을떄까지 채워지지 않기 때문
그리고 테스트니깐 50,000정도로 설정한다 200,000너무 오래걸린다.
또 갑자기 안되는데 url값에 파라미터가 달라졌음
쿠팡 시간이 지나면 channel이 변경되는 것 같음 이에 맞게 수정해주거나 이 부분도 랜덤값으로 선택되게 변경해줌
로그보니 잘 작성되었고 엑셀도 생성되는 것 같은데 이미지가 종료돼서 도커에 exec로 접근할 방법이 없다.
if os.path.exists(file_path):
print(f"파일 생성 성공: {file_path}")
else:
print("파일 생성 실패")
종료된 곳에서 파일을 생성해보니 잘나왔음

docker cp 75a83581a365:/app/product_list.xlsx /c/Users/user/Desktop/성공한 폴더 도커에서 cp 명령어를 이용해 복사한 다음 가져왔더니 성공했음


자주쓰는 명령어
docker logs e2c7604b6d95 | grep "price-value"
docker build -t kaki5507/randomcoupang:latest ./
docker run -v /c/Users/user/Desktop/Random:/app kaki5507/randomcoupang:latest
docker cp 75a83581a365:/app/product_list.xlsx /c/Users/user/Desktop/
'PlayGround' 카테고리의 다른 글
| [Docker] Github Action 자동 배포 (1) | 2024.11.16 |
|---|---|
| [Docker] 도커 Compose , yml 설정 파일 - 2 (2) | 2024.11.07 |
| [Docker] 도커 기본적인 이해, 복습 끝내기 (용어 정리 , 간단 명령어 , 실습 , 파일 생성 빌드) - 1 (2) | 2024.11.03 |
| [ Java , Js , xml ] 웹 서비스 보안 취약점 예제 (+고치기) (0) | 2024.10.15 |
| [캐시 메모리] 캐시 메모리 ? 파워 장치와 관련 역할 (2) | 2024.09.15 |