컴퓨터 자원을 물리적인 형태와는 독립적으로 사용할 수 있도록 만드는 기술 하나의 컴퓨터를 여러 대처럼 나눠서 쓰는 것
1. 하나의 컴퓨터에서 windows 와 linux를 동시에 실행하는 것처럼 가상 컴퓨터를 나눌 수 있음. 2. 자원을 효율적으로 활용 / 물리적인 서버 한 대에 가상 컴퓨터 여러 대를 올려서 서버 자원을 효율적으로 활용 가능 3. [ 하이퍼바이저 ] 이 소프트웨어가 물리적 자원을 가상화해서 여러 운영체제가 동시에 사용할 수 있게 해줌.
물리적인 컴퓨터 = 아파트 건물 가상 컴퓨터 = 아파트 안에 있는 각 세대
적고 생각해보니 그럼 클라우드랑 다른 점? 클라우드는 서비스(결과), 가상화는 기술(수단)
클라우드는 가상화 기술을 활용해서 제공하는 서비스 인터넷을 통해 컴퓨터 자원을 빌려씀.
AWS의 꽃 EC2는 무엇일까?
Amazon Elastic Compute Cloud 여서 EC2였다..
C가 두개여서 EC2로 불리는 것 또 처음알게된 사실
EC2는 크기 조정이 가능한 컴퓨팅을 클라우드에서 제공하는 웹 서비스임, 고로 해보면 좀 더 쉽게 클라우드 컴퓨팅 작업을 할 수 있음.
Amazon EC2의 간단한 웹 서비스 인터페이스를 통해 간편하게 필요한 용량을 얻을 수 있다.
언제사용하는지?
우리가 사용하는 게임서버 또는 웹서버 , 애플리케이션 서버를 구축할 때 EC2를 사용함.
비트코인 채굴도 가능한데 그럼 비트코인 채굴로 쓰는것도 가능하지 않을까?
AWS에서 서비스 제공안하고 비트코인 채굴하면 더 사업성에 좋지 않을까?
- 비트코인 채굴로만 사용하면 경제성이 떨어질 수 있음
(채굴난이도 시간 지나면 증가하며 장비 업글해야함 그러면 AWS 회사 손해볼 수 있음 또한 당연하게도 비트코인 채굴하는 것보다 수익이 안좋으면 회사 손실이 큼)
- 클라우드 서비스가 꾸준한 수익이고 안정성이 더 좋음 , 정부 규제로 AWS같은 대형 기업이 채굴 사업에 집중하면 규제 리스트에 영향도 크고 안좋을 수 있음.
FROM node:16-alpine as builder
WORKDIR '/app'
COPY package.json .
RUN npm install
COPY . .
RUN npm run build
FROM nginx
CMD --from=builder /app/build /usr/share/nginx/html
Dockerfile.dev
FROM node:16-alpine
WORKDIR '/app'
COPY package.json .
RUN npm install
COPY . .
CMD ["npm", "run", "start"]
3. 아마존 가입 후 IAM에서 역할 먼저 생성
- AWSElasticBeanStalk에서 멀티컨테이너,웹티어,워커티어 설정
AWS Elastic Beanstalk은 애플리케이션 배포 및 관리 간소화 해줌 PaaS임( 사용자가 인프라 관리 X)
복잡한 인프라 설정없이 빠르게 클라우드로 애플리케이션 배포 가능
서버 프로비저닝 , 로드 밸런싱 , 자동 스케일링
서버 프로비저닝 : 마치 컴퓨터 사서 운영체제 필요한거 설치 작업을 AWS가 해준다.
로드 밸런싱 : 들어오는 트래픽 여러 서버로 고르게 분배하여 서버 과부하 방지
자동 스케일링 : 트래픽 변화에 따라 서버의 개수를 자동으로 늘리거나 줄이는 기능
4. 검색에 elasticbeanstalk으로 간다.
환경 생성해준다.
5. IAM 가서 사용자도 생성
보안 자격증명에서
엑세스 키 만들어야 함
만들면 액세스키랑 비밀 액세스 키 생성된다.
필요하기 때문에 개인 보관
6. S3 이동
클라우드 스토리지 서비스 , 데이터 인터넷에 안전하게 저장하고 관리 , 디지털 저장소
자동으로 생성된 버킷에 들어간다.
객체소유권에서 객체 라이터 , ACL 활성화됨 선택 잘되어있는지 확인
객체라이터 : 각 계정이 자신이 업로드한 데이터의 소유권과 관리를 계속 유지해야될 때
ACL 활성화 : 객체 소유자가 버킷 소유자와 다른 경우가 많아, 버킷 정책만으로 권한 관리가 어려운 경우
7. 리액트 빌드 테스트 성공하면 방금 만든 elasticbeanstalk에서 바로 배포(저장소 필요 깃헙생성)
8. 원격 저장소와 react app 연결 후 소스코드 올려줌
9. 올라간거 확인하고 Travis CI 대신 Github action 이용할 것
프로젝트에 .github 폴더와 workflows 폴더 그리고 deploy.yml 파일 작성한다.
10. deploy.yml에 필요한 계정 비밀 액세스 키 등은 깃허브 settings에서 Secrets and variables에서 설정가능하다.
Actions에서 추가 가능
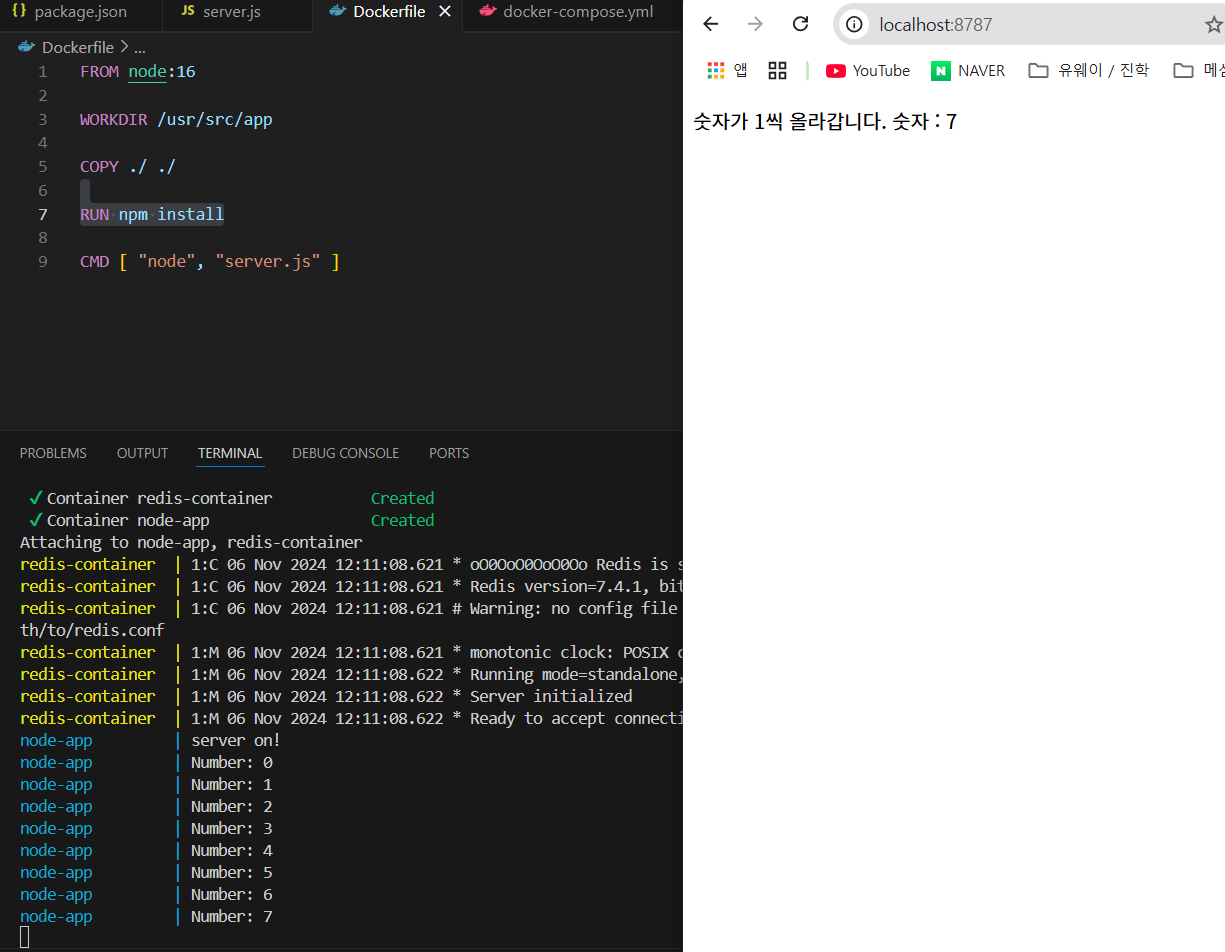
깃 액션에서 자동으로 배포해주는 모습을 보여준다. 현재는 에러나서 해결 해야함.
도커 비밀번호가 틀려서 제대로 동작하지 못했음.
비밀번호 변경 후elasticbeanstalk에서도 성공한모습을 볼 수 있다
성공해서 도메인 들어갔는데 도커랑 연결이 되었다는 화면만 뜰분 내가 배포한 리액트 기본 이미지는 나오지 않았음
원인 분석해보니 Elastic Beanstalk의 애플리케이션 이름과 환경이 설정이 되지 않았음
**actions/checkout**은 GitHub 리포지토리에서 코드 작업을 할 때 필수적인 기본 액션입니다.
**einaregilsson/beanstalk-deploy**는 AWS Elastic Beanstalk에 애플리케이션을 배포하는 데 사용되는 액션입니다.
따라서, actions/checkout은 코드 다운로드에 사용되고, einaregilsson/beanstalk-deploy는 배포를 위한 액션입니다.
uses 에서도 actions를 배포를 위한 액션으로 바꿔줘야한다.
v20,v18 버전으로 바꿔봤으나 둘 다 빌드 실패했음 어느게 문제일까?
로그탭에서 로그 전체를 받아서 분석해본결과 docker-compose.yml파일에 version삭제하라해서 삭제했는데도 안됨..
FROM이 from으로 되어있다고 했는데 그건 문제가 아니였고
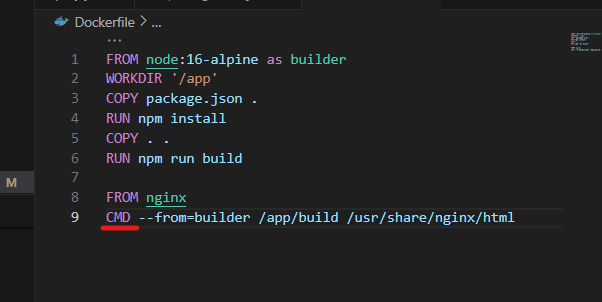
ngnix로 정적 파일 디렉토링해서 옮겨야되는데 CMD로 적어서 오류난거였음 COPY로 수정한다.
User-agent : Googlebot 구글 봇에 대해 규칙이 적용되어 있음 (*이면 모든 봇에 대해 규칙 적용)
Allow : 경로에 있는 페이지 크롤링해도 좋다.
Disallow : 경로에 있는 페이지는 크롤링 하지 말아달라.
내가 볼 곳은 상품페이지 인데 Allow로 되어있는것을 확인할 수 있음
내 user-agent 확인 방법
개발자 도구를 열고 navigator.userAgent 입력한다.
1. Selenium 설치
pip install selenium
pip : 파이썬 패키지 설치하고 관리할 수 있는 관리 도구
자동화 테스트 셀레니움 설치
2. chromedriver_autoinstaller 설치
pip install chromedriver-autoinstaller
ChromeDriver의 버전을 자동으로 맞추어주는 라이브러리.
셀레니움을 Chrome에서 자동화할 때, ChromeDriver의 버전은 Chrome버전과 일치해야되므로 버전 호환성 문제를 해결해줌.
$ pip show chromedriver-autoinstaller
Name: chromedriver-autoinstaller
Version: 0.6.4
Summary: Automatically install chromedriver that supports the currently installed version of chrome.
Home-page: https://github.com/yeongbin-jo/python-chromedriver-autoinstaller
Author: Yeongbin Jo
Author-email: iam.yeongbin.jo@gmail.com
License: MIT
Location: C:\Users\user\AppData\Local\Programs\Python\Python312\Lib\site-packages
Requires: packaging
Required-by:
제대로 설치 됐는지 확인하려면 show 명령어 통해 확인
3. 파이썬 코드 작성
import time
import random
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
import chromedriver_autoinstaller
시간,랜덤값 그리고 셀레니움 필요 설정 import
- webdriver : 웹 브라우저 제어 객체 (필수)
- By : 요소 찾을 때 (ID, CLASS_NAME , CSS_SELECTOR) javascript로 생각하면 documents.getElementsById 같은 느낌
- Keys : 키보드 입력 모방할 수 있는 기능 제공
처음실행될 때 호환성 문제를 해결하기 위해서 ChromeDriver를 자동으로 설치 해야함.
chromedriver_autoinstaller.install()
나는 Docker에서 사용할것이므로 GUI가 필요없다. 그러므로 옵션 추가해줘서 백그라운드에서 작업하게 해줘야함.
Keys.TAB - 탭 키 Keys.BACKSPACE - 백스페이스 키 Keys.DELETE - 삭제 키 Keys.HOME - 홈 키 Keys.END - 엔드 키 Keys.PAGE_DOWN - 페이지 다운 키 Keys.PAGE_UP - 페이지 업 키 Keys.ARROW_UP - 위쪽 화살표 키 Keys.ARROW_DOWN - 아래쪽 화살표 키
등등이 있음.
검색 후 페이지 로드되는 것 기다려야함
time.sleep(2)
내가 원하는 가격 설정 후 while문을 이용해서 채워질때까지 반복문을 실행
로켓배송 붙은 상품상품 클래스명로켓배송과 로켓배송 없는 li 태그 분석
data-is-rocket 값이 true이면 로켓배송 아니면 일반배송임
해당 div에 있는 name 값과 price-value가 필요하니 변수 선언해서 가져온다
price는 누적해서 내가 설정한 값을 넘기면 안되므로 int형으로 바뀐 후 누적해서 더해준다.
#랜덤으로 로켓배송 상품 선택
item = random.choice(rocket_items)
try:
#상품 이름 금액 추출
item_name = item.find_element(By.CSS_SELECTOR, "div.name").text
item_price_txt = item.find_element(By.CSS_SELCTOR, "strong.price-value").text
#int로 변환
item_price = int(item_price_txt.replace(",", ""))
# total_price 넘으면 안됨
if now_price + item_price <= total_price:
product_list.append({"name" : item_name , "price" : item_price})
now_price += item_price
items_cnt += 1
except Exception as e:
print("예외가 발생하였습니다." , e)
2개를 찾았으면 끝나고 다음 페이지에서 또 2개를 채워줘야함 , 클릭한 뒤 랜더링 되는 시간 2초 빼준다.
try:
next_button = driver.find_element(By.CSS_SELECTOR, "a.btn-next")
next_button.click()
time.sleep(2) # 랜더링 대기
except Exception as e:
print("예외가 발생하였습니다." , e)
엑셀로 만들어서 쓰기 위해 Pandas 라이브러리 추가해준다.
pandas가 할 수 있는 일
1. 엑셀 파일 읽고 쓰는 작업
2. CSV 파일을 읽고 쓰는 작업
3. 데이터 정렬 , 그룹화 , 필터링 등등
4. 수치형 데이터 분석과 같은 다양한 데이터로 반환
pip install pandas
판다스깔고 임포트 시킨 후 사용
df = pd.DataFrame(product_list) # product_list를 DataFrame으로 변환
df.to_excel("product_list.xlsx", index=False) # 엑셀 파일로 저장
apt-get install -y는 필요한 패키지를 설치. -y는 모든 응답에 "y"로 대답하여 넘어가는 것
curl : 웹에서 파일 다운로드 또는 API 호출을 통해 데이터를 받아오거나 전송할 때 주로 사용
WORKDIR 작업디렉토리 생성
COPY로 먼저 txt 복사 이후 내용 설치 (캐시 비우기 옵션 추가 이미지 가볍게 하기 위해)
컨테이너 안에서 실행시켜야되므로 COPY해서 py실행
WORKDIR /app
# requirements.txt 복사 및 라이브러리 설치
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
# 크롤러 스크립트 복사
COPY crawlling.py .
# 환경 변수 설정
ENV CHROME_BIN=/usr/bin/chromium
ENV CHROMEDRIVER_PATH=/usr/bin/chromedriver
# 크롤러 실행
CMD ["python", "crawler.py"]
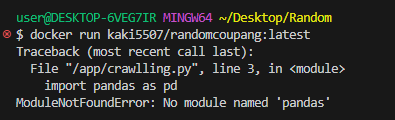
빌드하고 실행하는데 에러뜬다.
확인해보니 크롤러 실행하는 파일 이름 달랐음
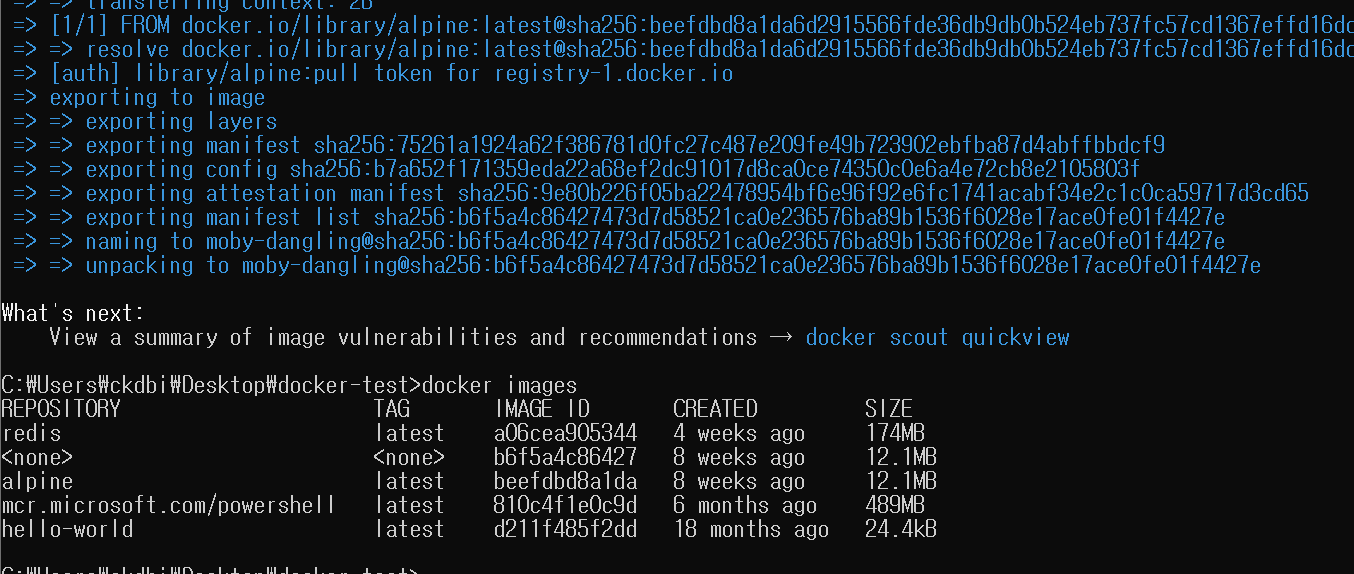
도커 컨테이너 내부에 pandas 없다는 오류
확인해보니 requirements.txt에 필요한 파이썬 패키지를 넣지 않았음
하지만 실행해도 아무일 일어나지 않음
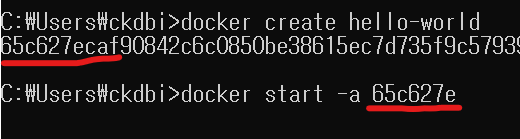
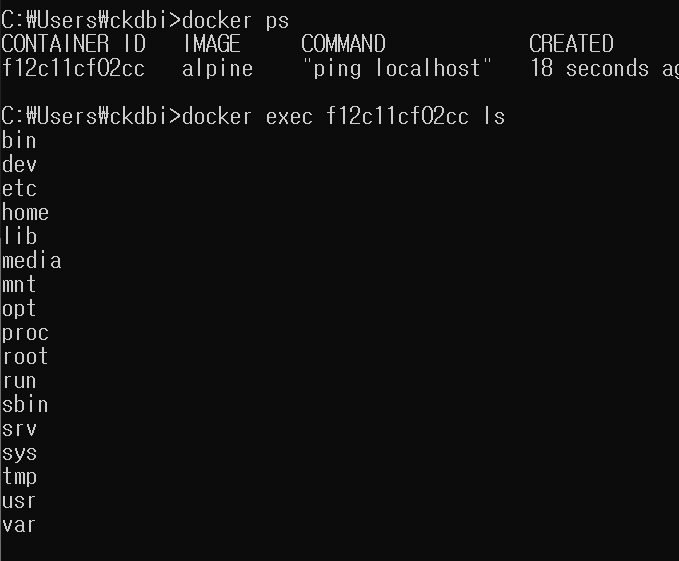
도커 컨테이너에서 생성한 파일은 컨테이너 파일 시스템에 저장! 컨테이너가 종료되면 파일또한 역시 삭제 됨. 그래서 삭제 전에 호스트 시스템에서 확인하고 싶다면 실행된 상태에서 파일을 복사해야함.
docker cp <컨테이너_ID>:/app/파일명 /호스트/경로/
C:\Users\user
호스트 경로는 바탕화면에 할거면 이런식으로 자기 컴퓨터에 맞게 cp라는 명령어로 copy복사한다는 것
또는 호스트의 디렉토리와 공유하는 방법이 있음
접근이 거부되었다고 나옴
내부코드에서 driver = webdriver.WebDriver 문법 맞지 않다고 나옴 수정 필요
Name으로 적으면 안됨 NAME으로 적어야 함
페이지로드가 되기전에 p를 불러서 그런지 계속해서 오류가 난다
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
# 랜덤 User-Agent 리스트
user_agents = [
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:89.0) Gecko/20100101 Firefox/89.0",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/15.0 Safari/605.1.15",
"Mozilla/5.0 (Linux; Android 10; SM-G950F) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.77 Mobile Safari/537.36",
"Mozilla/5.0 (iPhone; CPU iPhone OS 14_0 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/14.0 Mobile/15E148 Safari/604.1",
# 추가 User-Agent를 여기에 추가할 수 있습니다.
]
# 랜덤으로 User-Agent 선택
random_user_agent = random.choice(user_agents)
그래서 과자를 입력 한뒤 작업부터 하니깐 불러와지긴하는데 name값이랑 value값을 잡지 못함
#driver.get("https://www.coupang.com/") #랜더링이 전체가 되지않고 카테고리까지 돼서 수정
driver.get("https://www.coupang.com/np/search?component=&q=%EA%B3%BC%EC%9E%90&channel=user")
const express = require('express'); // express 가져와줌
const PORT = 8080;
// express 앱 생성
const app = express();
app.get('/', (req,res) => {
res.send("Hello World");
});
app.listen(PORT); // 설정 된 포트에서 앱실행해야됨
이제 도커파일 생성할 것
FROM RUN CMD ! 위에 예제했던대로 먼저 해야 될 것 작성
# 베이스 이미지 명시
FROM node:10
RUN npm install
CMD ["node", "server.js"]
npm install을 하려면 npm이 가지고 있는 이미지가 필요한데 그게 node 이미지임
node 이미지는 npm도 있고 다른것도 많음
npm Node.js 모듈 웹에서 받아서 설치하고 관리해주는 프로그램
npm install은 package,json에 적혀있는 종속성들을 웹에서 자동으로 다운 받아 설치
build해서 성공 하지만 실행 시 되지 않았음
C:\Users\ckdbi\Desktop\nodejs-docker>docker run ec45af266bd5c5
internal/modules/cjs/loader.js:638
throw err;
^
Error: Cannot find module '/server.js'
at Function.Module._resolveFilename (internal/modules/cjs/loader.js:636:15)
at Function.Module._load (internal/modules/cjs/loader.js:562:25) at Function.Module.runMain (internal/modules/cjs/loader.js:831:12)
at startup (internal/bootstrap/node.js:283:19)
at bootstrapNodeJSCore (internal/bootstrap/node.js:623:3)
server.js를 찾을 수 없다라고 나온다.
Node 베이스 이미지로 node:10을 입력했고 이걸로 임시 컨테이너를 만들려고 하고 , 환경을 하드 디스크에 넣어주는데
npm install을 하려고 할때 package.json이 없다고 나옴 컨테이너안에 있는것이 아니고 package.json이 바깥에 있어서 하드 디스크가 들어있지 않음. package.json을 컨테이너 안으로 넣어줘야 사용이 가능
COPY해서 사용해야 됨.
FROM RUN CMD 이렇게 있었는데 COPY 부분을 추가해줘야함
# 베이스 이미지 명시
FROM node:10
COPY package.json ./
RUN npm install
CMD ["node", "server.js"]
이렇게 설정해두고 다시 빌드해본다.
docker build -t kaki5507/nodejs ./
$ docker run kaki5507/nodejs
internal/modules/cjs/loader.js:638
throw err;
^
Error: Cannot find module '/server.js'
at Function.Module._resolveFilename (internal/modules/cjs/loader.js:636:15)
at Function.Module._load (internal/modules/cjs/loader.js:562:25) at Function.Module.runMain (internal/modules/cjs/loader.js:831:12)
at startup (internal/bootstrap/node.js:283:19)
at bootstrapNodeJSCore (internal/bootstrap/node.js:623:3)
또 못찾음 .. server.js도 밖에서 있어서 그런 것 안에다 넣어줘야한다.
dockerfile 다시 수정
# 베이스 이미지 명시
FROM node:10
COPY ./ ./
RUN npm install
CMD ["node", "server.js"]
실행된 화면을 볼 수 있음
console.log("서버 돌아가고 있음")
app.listen(PORT); // 설정 된 포트에서 앱실해애됨
표시가 안나서 console.log 하나 찍어준다음 다시 빌드해서 도커 실행
그리고 localhost8080해서 들어갔는데 뭐 나오는 건 없음 해당 포트 구문 8080 hello world 찍어주는 화면이 나와야하는데
왜 접근을 못하는지 ? - 현재 포트가 매핑되어 있지 않기 때문
우리가 8080을 준다고 해도 컨테이너안에 있는 네트워크 8080에 들어갈 수 있는것이 아님
매핑을 시켜줘야지 들어갈 수 있다.
-p : 포트 매핑 명령어를 이용하여 들어갈 수 있다.
docker run -p 5000 : 8080 이미지 이름
5000번으로 매핑 후 브라우저에서 접속하는 모습
도커 워크디렉토리
FROM WORKDIR COPY RUN CMD
무슨 옵션인지 ? 왜 필요할까 ?
이미지안에서 어플리케이션 소스 코드를 가지고 있을 디렉토리를 생성하는 것
COPY 한것들이 이미지로 루트로 들어오게 됨
이러면 원래 루트 디렉토리에 있는 파일이 만약 이름이 같을 경우 COPY한 파일이 덮어써질 수 있음
+ 너무 복잡함
이러한 문제를 해결하기 위해서 WORKDIR를 설정해서 깔끔하게 작성한다.
# 베이스 이미지 명시
FROM node:10
WORKDIR /usr/src/app
COPY ./ ./
RUN npm install
CMD ["node", "server.js"]
다시 이미지 빌드
워크디렉토리로 바로 연결돼서 정리된게 보임찾아서 들어가보면 파일들 잘 정리되어 있음
도커를 계속해서 빌드해야되는건가 ...
docker run -d -p 5000:8080 kaki5507/nodejs
-d 옵션 바로 빠져나오게 하는 것 포트 매핑
const express = require('express'); // express 가져와줌
const PORT = 8080;
// express 앱 생성
const app = express();
app.get('/', (req,res) => {
res.send("Hello World2222222");
});
console.log("서버 돌아가고 있음")
app.listen(PORT); // 설정 된 포트에서 앱실해애됨
이렇게 Hello World222222가 출력되게 하고 싶음( 또 빌드 해야함 비효율적 )
# 베이스 이미지 명시
FROM node:10
WORKDIR /usr/src/app
# package.json COPY 먼저
COPY package.json ./
RUN npm install
# RUN 밑으로 내림
COPY ./ ./
CMD ["node", "server.js"]
패키지 부분을 먼저 카피를 해주고 package.json부분을 카피함
지금까지는 npm start하면서 package.json을 계속 다시 받은거였음
RUN 위에 COPY로 먼저 안바뀔 설정들을 받아두는게 좋음
나머지 변경되는 소스들을 아래로 내려서 캐시를 이용해서 받아 빠른 수정사항을 적용시킬 수 있었음.
CACHED 사용 부분
Docker Volumes이란?
COPY는 내 로컬에있는 파일을 도커 컨테이너로 옮기는 것인데
Volume은 도커 컨테이너가 내 로컬을 참조하는 것
cmd 에서 명령어
C:\Users\ckdbi\Desktop\nodejs-docker>docker run -d -p 5000:8080 -v /usr/src/app/node_modules -v %cd%:/usr/src/app kaki5507/nodejs
git bash에서는 $(pwd) 이용
docker run -d -p 5000:8080 -v /usr/src/app/node_modules -v $(pwd):/usr/src/app kaki5507/nodejs
docker run -d -p 5000:8080 -v /usr/src/app/node_modules -v %cd%:/usr/src/app kaki5507/nodejs
-v /usr/src/app/node_modules : 내 usr/src/app에는 node_modules 없어서 제외
(호스트 경로 지정안되어 있음 , 이 경우 Docker는 해당 볼륨을 데이터 볼륨으로 처리 , 호스트의 파일 시스템과는 독립적으로 데이터 유지)
-v %cd%:/usr/src/app : 나머지는 내 디렉토리 %cd%에서
(현재 디렉토리 가르킴 %cd% 동기화되어 상호 공유)
근데 윈도우에서 Volume이용하면 바로 바뀌지 않는다 무슨 문제인지 cmd로 빌드했을 경우 잘됨
CMD 결과
경로 호환성 문제: Windows와 Git Bash 간 경로 처리 방식 차이로 Docker가 파일을 제대로 마운트하지 못함.
권한 문제: Git Bash에서 Docker가 파일 시스템 권한을 올바르게 인식하지 못해 동기화 실패.
winpty docker run -d -p 5000:8080 -v $(pwd):/usr/src/app kaki5507/nodejs
1.
권한 문제 라고 생각했을 경우 해결 방법으로 winpty를 사용해서 windows 응용 프로그램과의 호환성 문제를 해결할 수 있다고 한다.
바로 적용해본다.
결과 : 빌드전으로 돌아감 Hello World가 나옴
2.
docker run -d -p 5000:8080 -v "$(cygpath -w "$(pwd)")":/usr/src/app kaki5507/nodejs
$(cygpath -w "$(pwd)") : 현재 디렉토리 Windows 경로로 변환
이 문제는 아닌 것 같다 해결 안됨. 결과 동일.
3.
Nodemon 사용하기 Node.js 애플리케이션이 자동으로 파일 변경을 감지하도록 설정
FROM node:14
WORKDIR /usr/src/app
COPY package*.json ./
RUN npm install -g nodemon
RUN npm install
COPY . .
CMD ["nodemon", "server.js"]
응답분할이란 악의적인 사용자가 서버에 잘못된 입력을 제공하여 http 응답을 두 개로 분할하여 공격함.
헤더 조작해서 서버가 두 개 이상의 응답을 반환하도록 요구하여 정보를 탈취해갈 수 있음.
import java.io.IOException;
import javax.servlet.ServletException;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
public class VulnerableServlet extends HttpServlet {
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
// 사용자 입력을 URL 파라미터로 받음
String userInput = request.getParameter("user");
// 취약한 응답 헤더 설정 (사용자 입력을 검증 없이 헤더에 포함)
response.setHeader("Set-Cookie", "user=" + userInput);
// 응답 내용
response.getWriter().println("Welcome " + userInput);
}
}
해결방법은 응답에 escape 처리한다.
// 사용자 입력을 인코딩 처리하여 응답 분할을 방지
String safeInput = StringEscapeUtils.escapeHtml4(userInput);
이런식으로 escape처리하여,HTTP 헤더나 HTML 응답에 안전하게 포함시킨 후 보냄
2. 경로 조작 및 자원 삽입
취약한 코드 외부 입력(name)이 삭제할 파일의 경로설정에 사용되고 있습니다. 만일 공격자에 의해 name의 값이 ../../../rootFile.txt와 같은 값이면 의도하지 않았던 파일이 삭제되어 시스템에 악영향을 줍니다.
의도하지 않는 파일이 삭제되면 안됨!
public void bad(Properties request)
{
//...
String name = request.getProperty("filename");
if (name != null)
{
// 보안 약점: 외부 입력값이 필터링 없이 파일 생성 인자로 사용
File file = new File("/usr/local/tmp/" + name);
if (file != null) file.delete();
}
//...
}
getCanonicalPath() 메서드를 사용하여 실제 파일 경로를 확인한 후,기본 디렉토리 경로와 비교하여 사용자가 상위 디렉토리로 벗어나지 않도록 방지함.
상위 디렉토리를 벗어나지 않게하면 다른 중요한 파일들에 접근 못함!
이러한 코드를 아래와 같이 경로가 벗어나는지 확인하는 코드로 바꿔 수정
String baseDir = "/var/www/app"; // 기본 경로를 설정
String strPath = "../etc/passwd"; // 사용자가 입력한 경로 (악의적인 경우)
// 파일 경로 검증
File file = new File(baseDir, strPath); // 기본 경로와 사용자 입력 경로를 합침
String canonicalPath = file.getCanonicalPath(); // 실제 파일 경로 얻기
// 사용자가 설정한 경로가 baseDir을 벗어나는지 확인
if (!canonicalPath.startsWith(new File(baseDir).getCanonicalPath())) {
throw new SecurityException("잘못된 경로입니다!");
}
// 경로가 유효한 경우에만 디렉토리 생성
if (!file.isDirectory()) {
file.mkdirs(); // 안전하게 디렉토리 생성
}
3. 널 포인터 역참조
자바에서 null 값을 참조하는 객체에 접근하려 할 때 발생하는 오류입니다. 즉, 객체가 생성되지 않았거나 초기화되지 않은 상태에서 해당 객체의 메서드나 변수를 사용하려 할 때 NullPointerException(NPE)이 발생하게 됩니다.
public void good(ServletRequest request)
{
String myString = null;
if ((myString != null) && (myString.length() > 0)) {
IO.writeLine("The string length is greater than 0");
}
}
else로 대입안하거나 continue로 그냥 넘기고 다음 반복문으로 진행 시킴
null 할당안해도 될 것 같음.. 오류나는지 확인 필요
4. 부적절한 자원 해제 ( IO )
프로그램의 자원, 예를 들면 열린 파일디스크립터(Open File Descriptor), 힙 메모리(Heap Memory), 소켓(Socket), DB 등은 유한한 자원입니다. 이러한 자원을 할당받아 사용한 후, 더 이상 사용하지 않는 경우에는 적절히 반환하여야 하는데, 프로그램 오류 또는 에러로 사용이 끝난 자원을 반환하지 못하는 경우입니다.
예시) ByteArrayInputStream fileOut = new ByteArrayInputStream(out.toByteArray()); 여기서는 자원누수가 발생할 수 있음. 적절이 해제 안되면 프로그램이 유한한 시스템 자원을 소진할 수 있다고함. ByteArrayInputStream 내부적으로 힙 메모리를 사용함. 파일 핸들로 운영 체제에서 한 번에 열수있는 파일의 수를 제한을 둬 Too Many Open Files와 같은 오류가 발생 가능.
해결 방법으로는
try (ByteArrayInputStream fileOut = new ByteArrayInputStream(out.toByteArray())) {
// fileOut 사용
} catch (IOException e) {
// 예외 처리
}
이런식으로 객체의 자동으로 자원을 해제할 필요는 없지만, 다른 자원과의 일관성을 위해서 try-with-resources구문으로 자동으로 닫아주고 코드에서 자원 누수를 방지할 수 있음.
5. 신뢰되지 않는 URL 주소로 자동 접속 연결
public void connectToUrl(String urlString) {
try {
// 신뢰되지 않은 외부 URL로 연결
URL url = new URL(urlString);
HttpURLConnection connection = (HttpURLConnection) url.openConnection();
connection.setRequestMethod("GET");
int responseCode = connection.getResponseCode();
System.out.println("Response Code: " + responseCode);
// 연결 후 처리
BufferedReader in = new BufferedReader(new InputStreamReader(connection.getInputStream()));
String inputLine;
StringBuffer content = new StringBuffer();
while ((inputLine = in.readLine()) != null) {
content.append(inputLine);
}
in.close();
System.out.println("Response Content: " + content.toString());
} catch (Exception e) {
System.out.println("Error occurred: " + e.getMessage());
}
}
보안 개선 방법은 화이트리스트로 특정 도메인 , ip를 미리 작성한 후 그것과 비교
public void connectToTrustedUrl(String urlString) {
try {
// 신뢰할 수 있는 도메인 검증
if (!urlString.startsWith("https://trusted.com")) {
throw new IllegalArgumentException("Untrusted URL");
}
URL url = new URL(urlString);
HttpURLConnection connection = (HttpURLConnection) url.openConnection();
connection.setRequestMethod("GET");
int responseCode = connection.getResponseCode();
System.out.println("Response Code: " + responseCode);
// 연결 후 처리
BufferedReader in = new BufferedReader(new InputStreamReader(connection.getInputStream()));
String inputLine;
StringBuffer content = new StringBuffer();
while ((inputLine = in.readLine()) != null) {
content.append(inputLine);
}
in.close();
System.out.println("Response Content: " + content.toString());
} catch (Exception e) {
System.out.println("Error occurred: " + e.getMessage());
}
}
6. 크로스사이트 스크립트 (XSS Error Message)
{
response.sendError(404, "param " + data);
}
data값에 악의적인 스크립트 포함시켜 사용자에게 실행을 유도 시킬 수 있으므로 replace를 작성하자
data.replaceAll("<","")
7.오류 상황 대응 부재
try catch나 메소드 반환값에 대한 적절한 예외처리 필요합니다, catch 블록이 비어있는 문제 해결 catch블록에 들어가는 내용은 - 오류로깅 : 발생한 예외의 정보를 로그로 남기는 것이 좋음 - 사용자에게 알리기 - 복구로직 : 기본값으로 설정하는 로직을 넣거나 다시 시도하는 로직을 넣어줌
8. 오류 상황 미수신
예외를 발생시키면 반드시 처리하게 throw new ~~~Exception시에 해당 Exception처리하는 문 필요합니다.
9.주석문 안에 포함된 시스템 주요정보
주석안에 원래 로직 또는 변수명 id,pass 같은 값 있으면 제거해야 됨.
10.중요한 자원에 대한 잘못된 권한 설정 (File)
File file = new File(sPath);
if (file.exists() == false) {
file.mkdirs();
}
해당 코드를
File dir = new File(sPath);
// 1. 디렉토리 존재 여부 체크
if (!dir.exists()) {
// 2. 먼저 권한 검증 (필요시, 부모 디렉토리나 경로에 대한 접근 권한도 검증)
if (!dir.getParentFile().canWrite()) {
throw new SecurityException("Cannot write to the parent directory.");
}
// 3. 디렉토리 생성
boolean success = dir.mkdirs();
if (success) {
// 4. 생성 후 권한 설정
boolean isExecutableSet = dir.setExecutable(false, true); // 모든 사용자에게 실행 권한 없음
boolean isReadableSet = dir.setReadable(true); // 모든 사용자에게 읽기 권한 부여
boolean isWritableSet = dir.setWritable(false, true); // 모든 사용자에게 쓰기 권한 없음
if (isExecutableSet && isReadableSet && isWritableSet) {
System.out.println("Directory created and permissions set successfully.");
} else {
throw new SecurityException("Failed to set the directory permissions.");
}
} else {
throw new IOException("Failed to create the directory.");
}
} else {
System.out.println("Directory already exists.");
}
디렉토리 생성 전에 권한 검증을 수행하면 보안적인 위험을 줄일 수 있음.
권한 검증 후 디렉토리를 생성하므로 , 권한이 제대로 설정되지 않은 디렉토리가 생성되거나 사용하는 시스템에 위험을 초래할 가능성 있음.
근데 보통은 생성한 후에 한다고함 code-ray에서는 후에 사용하면 계속 잡혀서 해당 변수들을 위로 넣었는데 그건 올바르지 않는 방법
생성한 후에 하는 이유는
- 권한 설정은 이미 존재하는 디렉토리나 파일에 적용되는 것이 일반적 디렉토리가 없으면 검증할 이유가 없기 때문..
11. 적절하지 않은 난수값 사용
Math.random()은 예측이 가능한다고해서 사용하면 안된다고 한다.
보안 대책으로 난수값 예측이 어려운 함수 사용해야함.
// 랜덤 인덱스 생성 함수
function getRandomIndex(length) {
const array = new Uint32Array(1); // 32비트 정수 배열 생성
window.crypto.getRandomValues(array); // 보안적인 난수 생성
return array[0] % length; // 배열 길이에 맞춰 인덱스 반환
}